

Note: This was written in December 2023, but this is an ever-changing space, so please contact your local LEAP support engineers if you would like to discuss your specific needs!
Working at the bleeding-edge of engineering simulations, LEAP’s engineers are frequently asked for advice from our clients across many different industries, who are looking to successfully navigate the balance between cost and optimal solver performance when purchasing new hardware. The following advice is primarily based on LEAP’s accumulated recent experience with a particular focus on CFD workloads (Ansys Fluent), as FVM codes are capable of scaling incredibly well if the system is well designed. Other tools such as Ansys Mechanical or Electromagnetics have very similar requirements, with a few notable differences/exceptions:
- FEA codes generally do not scale as well as FVM, so do not expect to see the same degree of speedup as shown in some of the graphs below.
- Mech and EM both perform a large quantity of I/O during the solve, thus it is imperative that the system has a very fast storage device (e.g. NVMe SSD) used as the scratch/project directory.
- Ansys EM (HFSS and Maxwell 3D) need significantly more memory capacity than CFD.
- As of 2023 R2, Ansys Maxwell currently performs best on Intel due to broader support for optimised math libraries.
General high-level advice to optimise your solver performance:
- Memory bandwidth is the key performance specification in most situations. Populate every memory channel available in your system.
- Newer DDR5-based platforms are strongly preferred over DDR4. We do not recommend purchasing DDR4 systems unless strictly necessary due to supplier limitations.
- High base clock-speeds are important – do not buy low wattage CPUs with high core-counts.
- Ansys solvers should always be run on physical cores rather than individual threads (we often advise turning off multi-threading on dedicated workstations / servers).
- Ensure your working directories and scratch locations are on high-speed NVMe storage devices.
- Ensure you have a discrete GPU for pre/post processing.

Small systems – laptop/desktop for solving on 4 cores:
Here our goal is to obtain the maximum possible performance on 4 cores.
Primary considerations for a laptop:
- Choose a chassis with ample cooling (sorry, no thin/light ultrabook style laptops here…).
- Look for CPUs with a suffix beginning with “H” – these are the high-power versions, typically with TDPs of 35 W or higher.
- AMD parts from 6000 series support DDR5 – prefer 7040/8040 series for “Zen 4” cores (e.g. 7940HS).
- Intel parts from 12th generation onwards support DDR5 (https://www.intel.com/content/dam/support/us/en/documents/processors/core/Intel-Core-Comparsion.xlsx).
- We recommend a minimum of 32 GB of RAM, preferably 64 GB for the ability to launch larger jobs.
- NVMe storage – at least 1 TB to fit OS, software, and project data.
- Discrete GPU for display/visualisation purposes (NVidia preferred – wider support amongst Ansys tools).
For a gaming/consumer-class 4+ core build:
- ‘Gaming’ type systems are often quite suitable.
- High clock speeds (base > 4 GHz, turbo > 5GHz).
- DDR5 memory (faster is better – e.g. 6000 MHz), generally 64 GB is suitable – depending on the size of your simulation models.
- NVMe storage – at least 1 TB to fit OS, software, and project data.
- Discrete GPU for display/visualisation purposes (NVidia preferred – wider support amongst Ansys tools).
Both AMD and Intel have suitable options in this category:
- AMD Ryzen 7000 series (Zen 4).
- AMD 3D V-cache CPUs (7800X3D, 7950X3D) are particularly suitable as CFD workloads benefit greatly from large cache pools.
- Intel 12th, 13th and 14th gen Core series.
Small-medium systems – desktop/workstation for ~12 solver cores:
While it can be tempting to use a ‘gaming’ type system as above, there are a couple of new considerations to make here:
- It is best to avoid hybrid processor architectures with ‘performance’ and ‘efficiency’ cores – we want our simulations to be running on 12 identical high-performance cores. As such, Intel Core series processors are not generally recommended (for example, Intel 14900K has 8 ‘performance’ cores and 16 ‘efficiency’ cores).
- Memory bandwidth needs to be considered. Gaming/consumer CPUs only have 2 memory channels, which is likely to cause a bottleneck when distributing a simulation across 12 cores (6 cores per channel). We prefer to limit the ratio of cores/channel to 4:1, although the higher bandwidth afforded by DDR5 has somewhat alleviated this, so stretching to 6:1 can still be viable.
Given the above, you can either choose to use an AMD Ryzen 7000 series CPU with >= 12 cores paired with ~6000 MHz DDR5 (e.g. 7950X), or move up a tier to dedicated workstation equipment (Intel Xeon-W, AMD Threadripper).
For a gaming/consumer-class AMD Ryzen 12+ core build:
- 7900X (12 cores) or 7950X (16 cores).
- 7950X3D is also an option, although the additional cache is only located on 8 of the cores – this could cause load balancing issues similar to the Intel P/E cores (untested!).
- DDR5 memory (faster is better – e.g. 6000 MHz), generally 64 GB is suitable – note that higher capacities than this may result in lower speeds due to stability requirements when running multiple DIMMs per channel.
- NVMe storage – at least 1 TB to fit OS, software, and project data.
- Consider a second storage device to handle a large quantity of project files.
- Discrete GPU for display/visualisation purposes (NVidia preferred – wider support amongst Ansys tools).
For a dedicated workstation-class 12+ core build:
- AMD Threadripper:
- Non “Pro” versions suitable as 4 memory channels is sufficient for these relatively low core counts.
- 7000 series (DDR5) released late 2023, else use 5000 series (DDR4).
- Intel Xeon-W:
- Sapphire Rapids preferred (i.e. 2023+ models).
- Prioritise higher base clock speeds.
- Older DDR4 systems are okay as more channels are available to make up for the lower speeds, but as always DDR5 is strongly preferred.
- Make sure to use at least 4 memory channels:
- i.e. populate the motherboard with 4 individual DIMMs of memory.
- For example, if you want 64 GB of RAM, make sure to use 4x 16 GB DIMMs.
- Similarly, for 128 GB use 4x 32 GB.
- NVMe storage – at least 1 TB to fit OS, software, and project data.
- Consider a second storage device to handle a large quantity of project files.
- Consider mid-tier NVidia Quadro GPU (e.g. RTX A4000) for better display performance on large models. Can also be used for solver acceleration in specific circumstances, or can even replace the CPU entirely when using Fluent’s GPU solver (see dedicated section below).
Medium systems – workstations for ~36 solver cores:
Similar requirements to the workstation-class build in the previous section, with a few modifications.
For a dedicated workstation-class 36+ core build:
- AMD Threadripper Pro:
- Do not use the non “Pro” versions – these only have 4 memory channels.
- 7000 series (DDR5) released late 2023, else use 5000 series (DDR4).
- Intel Xeon-W:
- Sapphire Rapids preferred (i.e. 2023+ models).
- Many options, make sure to prioritise higher base clock speeds.
- Can also use server-grade parts (e.g. Xeon Gold/Platinum, AMD Epyc).
- Make sure to use at least 8 memory channels (12 for AMD Epyc 9004 series):
- i.e. populate the motherboard with 8 individual DIMMs of memory.
- For example, if you want 128 GB of RAM, make sure to use 8x 16 GB DIMMs.
- Similarly, for 256 GB use 8x 32 GB.
- Older DDR4 systems are okay as more channels are available to make up for the lower speeds, but as always DDR5 is strongly preferred. If stuck with older DDR4 platforms (particularly Intel), we recommend dual CPU setups – that way you will double the available memory channels from 6 to 12. This requires Xeon Gold/Platinum (or AMD Epyc), rather than the workstation-class W- series (or AMD Threadripper)
- NVMe storage – at least 1 TB to fit OS, software, and project data.
- Consider a second storage device to handle a large quantity of project files.
- Consider mid-tier NVidia Quadro GPU (e.g. RTX A4000) for better display performance on large models. Can also be used for solver acceleration in specific circumstances, or can even replace the CPU entirely when using Fluent’s GPU solver (see dedicated section below).
Large systems – workstations / servers / clusters for ~128+ cores:
Multi-CPU systems requiring server-grade parts. Larger core counts will require clustered nodes with high-speed interconnects. Our goal is to ensure that total system memory bandwidth is sufficient to support the increasing number of cores.
- AMD Epyc:
- 9004 series (Genoa) strongly preferred. 12 channels of DDR5, available with up to 96 cores per CPU; however, we do not recommend going beyond 64 core models due to memory bandwidth limitations.
- Older generations (7001/2/3) have 8 channels of DDR4 per CPU; we do not recommend going beyond 32 core models due to memory bandwidth limitations.
- Prioritise models with high base clock speeds.
- Significant performance gains can be obtained with 3D V-Cache “X” series parts, which have additional L3 cache – see dedicated section below.
- Intel Xeon Platinum:
- Sapphire Rapids (4th generation) strongly preferred. 8 channels of DDR5, available up to 60 cores per CPU; however, performance is expected to drop off at lower core counts than AMD 9004 series due to having fewer memory channels.
- Older generations have 8 channels of DDR4, and are only available up to 40 cores.
- Prioritise models with high base clock speeds.
- Significant performance gains can be obtained with “Max” series parts, which have on-chip HBM memory – see dedicated section below.
- Make sure to populate every single memory channel available:
- 6 DIMMs per CPU (12 total) for previous gen Intel
- 8 DIMMs per CPU (16 total) for current gen Intel or previous gen AMD.
- 12 DIMMs per CPU (24 total) for AMD 9004 series.

Maximising price to performance, up to ~128 cores:
- Build a single chassis machine with dual CPUs (some Intel processors can be used in quad CPU configurations, but we do not recommend this configuration due to reduced communication speeds between each CPU).
- Newer DDR5 systems based on AMD 9004 or Intel Sapphire Rapids can scale past 100 cores.
- Older DDR4 systems will be limited to total core counts of ~64. We do not recommend going down this route, as you will likely not be maximizing the value of 3 Ansys HPC packs.
Maximising outright performance:
- Build a multi-node cluster.
- Pick lower core-count CPUs to maximise memory bandwidth per core (preferably 10 GB/s per core or higher).
- Make use of advanced technologies such as AMD 3D V-cache or Intel HBM.
- Use high-speed interconnects such as InfiniBand, allowing for 100 GB/s + communication between each node.
Notes on advanced technologies – AMD 3D V-Cache and Intel HBM
These technologies are quite different, but ultimately target the same thing – improving performance for memory bandwidth bound applications. AMD’s approach triples L3 cache by stacking additional chiplets on top of core complexes (CCDs) – with the largest versions now pushing past 1 GB of cache per CPU. Intel’s approach is akin to adding a large L4 cache (i.e. an additional level between L3 cache and DRAM), which is available in capacities up to 64 GB per CPU.
AMD 3D V-Cache
Single node performance can be significantly improved – many benchmarks (note: previous gen 7003X series) show speedups of 10 to 30%, with one extreme even reaching to 80%:
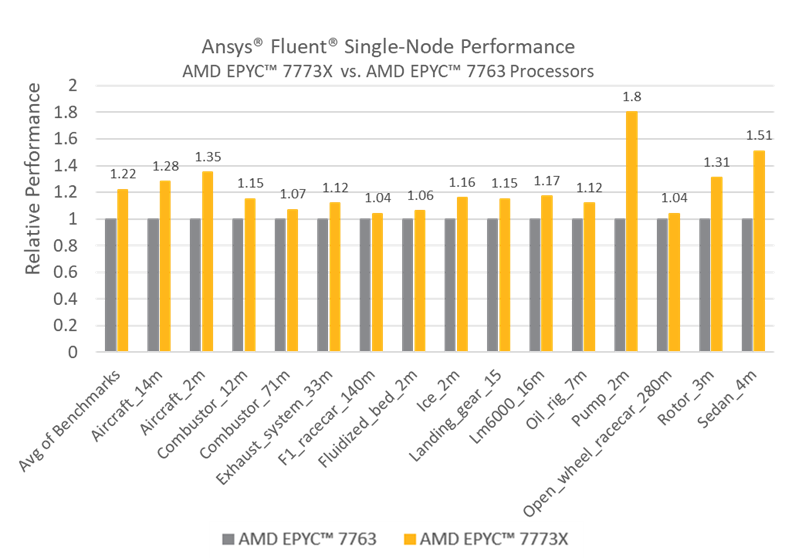
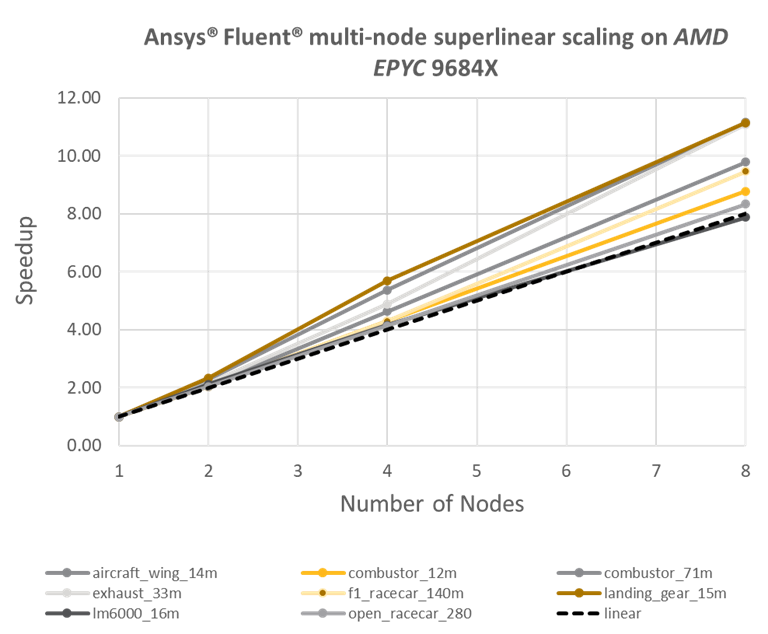
Multi-node performance can exhibit super-linear scaling – i.e. the speedup factor can outweigh the number of nodes. As more nodes are added to the system the total cache capacity increases accordingly, thus a higher proportion of the simulation is able to reside in cache rather than DRAM – one example below shows a speedup of 11x for a system consisting of 8 nodes:
Intel HBM (Xeon Max)
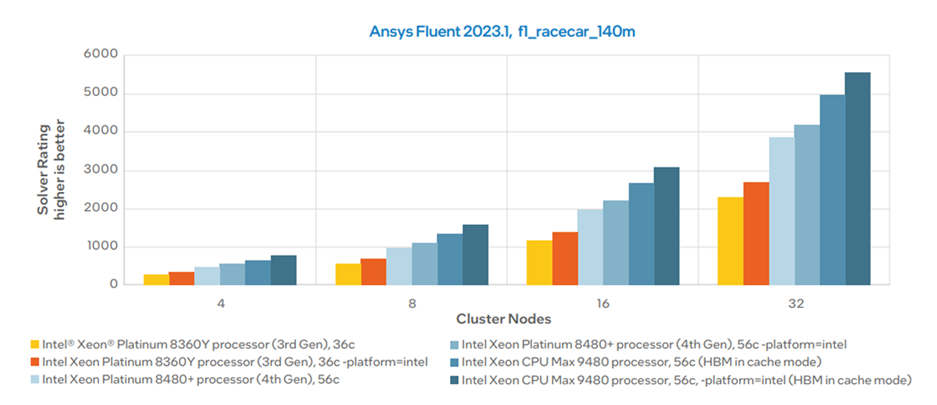
High-Bandwidth Memory (HBM) is a stacked DRAM technology with a very wide bus – 1024 bits per stack in contrast to 64 bits per DDR5 channel. Intel Xeon Max series CPUs use 4 stacks of 16 GB HBM2e, for a total of 64 GB operating at 1.22 TB/s; in conjunction with the 307.2 GB/s offered by the 8 standard DDR5 memory channels. In the following benchmark performed by Intel, the HBM processor (9480) is shown to outperform its regular counterpart (8480+) by over 30%:
Additional GPU Solver Considerations
GPUs can offer dramatic speedups for codes that are optimised to run in massively parallel environments. Particle-type solvers such as LBM, DEM, SPH etc. or raytracing solvers such as SBR+ are well suited to GPUs as parallelisation of the code is trivial; however, this is considerably more difficult to achieve with traditional CFD and FEA methods such as FVM and FEM.
Ansys have recently released a native multi-GPU (FVM) solver for Fluent which currently supports features such as sliding mesh, scale resolved turbulence, conjugate heat transfer, non-stiff reacting flows, and mild compressibility. Many benchmarks are showing that one high end GPU (e.g. NVidia A100) can offer similar performance to ~500 CPU cores – thereby offering significant hardware cost savings and enabling users to run large simulations in-house rather than having to rely on external clusters / cloud compute.
Ansys Rocky is another tool which is suited to GPUs. Rocky is primarily a DEM solver, capable of handling complex solid motion involving millions of particles; but also has an SPH solver for dealing with fluid motion of free-surface flows.
Both Fluent and Rocky have similar requirements for GPU specifications:
- NVidia GPUs are required as the code is written for CUDA (although AMD support is in development).
- Memory bandwidth is key – models with HBM can offer significantly higher bandwidth (multiple TB/s) than those with GDDR6 (up to 1 TB/s).
- Licensing is based on the number of “Streaming Multiprocessors” (SMs) present on the GPU, rather than cores on a CPU. Note that unlike CPUs, all SMs present on a GPU are used when launching a simulation – thus you will need to ensure that your license level is sufficient to use the entire card.
- GPUs with high double-precision (FP64) throughput may be required for certain scenarios – primarily non-spherical particles in Rocky. Note that while Fluent is generally used in double-precision mode, theoretical FP64 throughput is not actually a very important performance metric – the major bottleneck is still memory bandwidth. This means that even gaming GPUs with FP64 throughput that is 1:32 (or even 1:64) in comparison to FP32 can still perform admirably in double-precision simulations, so long as the memory bandwidth is adequate.
- Sufficient VRAM to fit the entire simulation onto the GPU without requiring system memory.
To put it simply:
- For ultimate performance, look at NVidia A100 / H100 or similar (HBM with very high bandwidth, high double-precision throughput)
- For more budget conscious hardware and licensing, look for cards with high memory bandwidth, high memory capacity, yet low SM counts. For example, NVidia RTX A5000 (24 GB, 768 GB/s, 64 SMs)
- For non-spherical particles in Rocky, look for cards with good FP64 throughput.
- Before choosing a GPU, contact LEAP’s support team to verify it is a good choice for your intended solver and licence structure.
Additional notes on Operating Systems:
The vast majority of Ansys tools can be run on either Windows or Linux (for a full list of supported platforms, please check the Ansys website: Platform Support and Recommendations | Ansys). We generally recommend performing pre- and post-processing on local Windows machines for a number of reasons:
- Ansys SpaceClaim and Discovery are currently only available on Windows.
- Display drivers tend to be more mature/robust on Windows.
- Input latency can be an issue if trying to manipulate large models over a remote connection to a workstation/server.
- Pre/post can be a waste of compute resources on a server – it is often desirable to keep as close to 100% solver uptime as possible.
Windows is also suitable for solving on small to moderately large machines (e.g. ~32 core workstations), however, we generally recommend dedicated Linux servers for larger solver machines and clusters – particularly if a multi-user environment is desired (e.g. queuing systems etc.).
Additional notes on Cloud Computing:
Cloud instance selection is dictated by the same hardware considerations mentioned above – particularly the “Large Systems” and “Advanced Technologies” sections. Here are a few additional considerations:
General:
- Be wary of vCPU counts – sometimes these are advertised as threads rather than cores. Some instances such as Azure HB series have multithreading disabled – this is ideal for Ansys solvers.
- It is often best to use an entire node rather than smaller instances – this will give you access to the full system memory bandwidth.
Azure:
- Ansys Cloud Direct is a fully managed service which provides a very easy way of getting started – available directly from within many Ansys tools.
- HBv3 and HBv4 for AMD 3D V-Cache CPUs (multi-threading disabled).
- InfiniBand for internode communication, which allows simulations to be scaled onto large clusters consisting of many nodes.
AWS:
- Talk to your LEAP account manager about using Ansys Cloud Gateway – this will get you up and running significantly faster, and provide easy access to best-practices / optimised solutions.
- C7a / C7i (or older C6a / C6i depending on cost/availability) can be used for single-node simulations.
- Hpc7a (or older Hpc6a) for multi-node simulations – these instances have faster interconnects.
- Note that AWS use EFA rather than InfiniBand for inter-node communication, this is not a plug-and-play solution for most Ansys solvers. Keep this in mind if you are intending on deploying a multi-node simulation environment outside of Ansys Cloud Gateway.



